To continue NPP training series here is my next topic: Data Structure on Nutanix with Hyper-V
If you missed other parts of my series, check out links below:
Part 1 – NPP Training series – Nutanix Terminology
Part 2 – NPP Training series – Nutanix Terminology
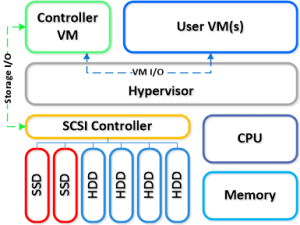
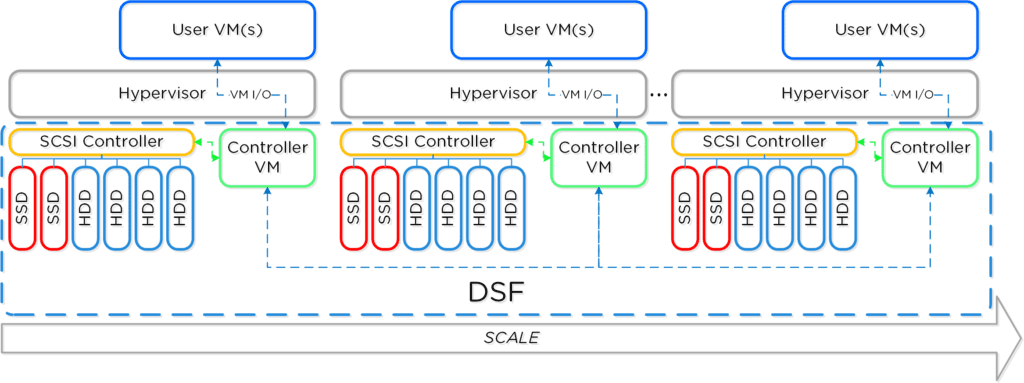
Cluster Architecture with Hyper-V
To give credit due, most of the content was taken from Steve Poitras’s “Nutanix Bible” blog as his content is the most accurate and then I put a Hyper-V lean to it and have updated the graphics for Hyper-V.
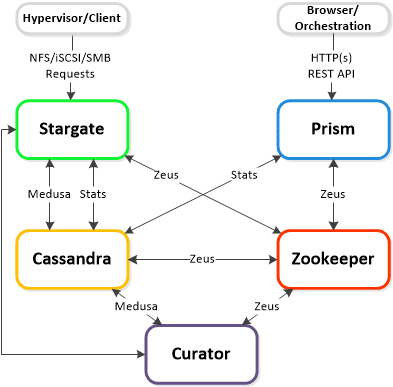
Data Structure on Nutanix
The NDFS (Nutanix Distributed Filesystem) is composed of the following high-level structs:
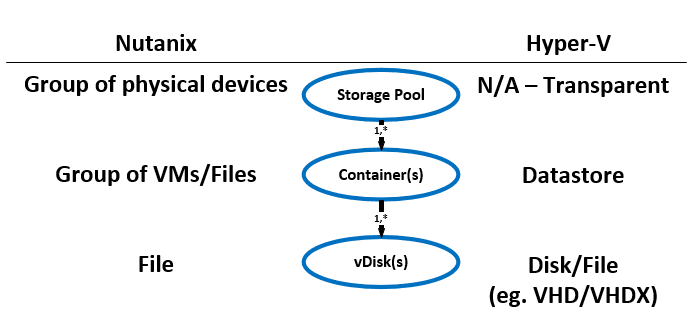
Storage Pool
- Key Role: Group of physical devices
- Description: A storage pool is a group of physical storage devices including PCIe SSD (Solid State Drive), SSD, and HDD (Hard Disk Drive) devices for the cluster. The storage pool can span multiple Nutanix nodes and is expanded as the cluster scales. In most configurations only a single storage pool is leveraged.
Container
- Key Role: Group of VMs/files
- Description: A container is a logical segmentation of the Storage Pool and contains a group of VM (Virtual Machine) or files (vDisks). Some configuration options (eg. (RF) Resiliency Factor) are configured at the container level, however are applied at the individual VM/file level. Containers typically have a 1 to 1 mapping with a datastore (SMB Share(s)).
vDisk
- Key Role: vDisk
- Description: A vDisk is any file over 512KB on NDFS including VM hard disks. vDisks are composed of extents which are grouped and stored on disk as an extent group.
Below we show how these map between NDFS and the Hyper-V:
Extent
- Key Role: Logically contiguous data
- Description: A extent is a 1MB piece of logically contiguous data which consists of n number of contiguous blocks (varies depending on guest OS block size). Extents are written/read/modified on a sub-extent basis (aka slice) for granularity and efficiency. An extent’s slice may be trimmed when moving into the cache depending on the amount of data being read/cached.
Extent Group
- Key Role: Physically contiguous stored data
- Description: A extent group is a 1MB or 4MB piece of physically contiguous stored data. This data is stored as a file on the storage device owned by the CVM (Controller Virtual Machine). Extents are dynamically distributed among extent groups to provide data striping across nodes/disks to improve performance.
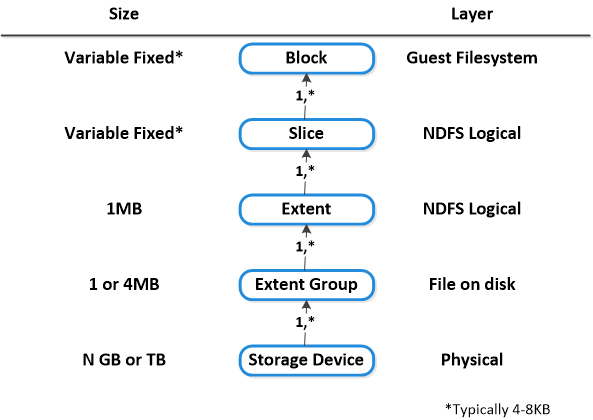
Below we show how these structs relate between the various filesystems:
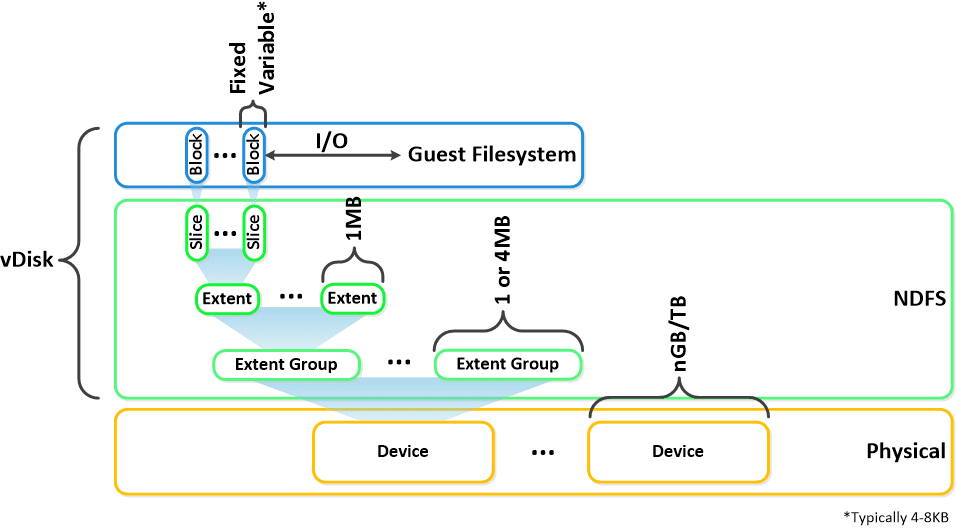
 Here is another graphical representation of how these units are logically related:
Here is another graphical representation of how these units are logically related:
 Next up, I/O Path Overview
Next up, I/O Path Overview
Until next time, Rob…