Hi all…It’s been a few weeks since my last blog post. I’ve been busy with some travel to Microsoft Technology Centers and working on the Nutanix Ready Program. Yesterday, Nutanix released NOS 4.5. This exciting upgrade adds some great features.. Sit back and get ready to enjoy the ride…release notes below.

| Table 1. Terminology Updates |
| New Terminology | Formerly Known As |
| Acropolis base software | Nutanix operating system, NOS |
| Acropolis hypervisor, AHV | Nutanix KVM hypervisor |
| Acropolis API | Nutanix API and Acropolis API |
| Acropolis App Mobility Fabric | Acropolis virtualization management and administration |
| Acropolis Distributed Storage Fabric, DSF | Nutanix Distributed Filesystem (NDFS) |
| Prism Element | Web console (for cluster management); also known as the Prism web console; a cluster managed by Prism Central |
| Prism Central | Prism Central (for multicluster management) |
| Block fault tolerance | Block awareness |
What’s New in Acropolis base software 4.5
Bandwidth Limit on Schedule
- The bandwidth throttling policy provides you with an option to set the maximum limit of the network bandwidth. You can specify the policy depending on the usage of your network.
Note: You can configure bandwidth throttling only while updating the remote site. This option is not available during the configuration of remote site.
Cloud Connect for Azure
- The cloud connect feature for Azure enables you to back up and restore copies of virtual machines and files to and from an on-premise cluster and a Nutanix Controller VM located on the Microsoft Azure cloud. Once configured through the Prism web console, the remote site cluster is managed and monitored through the Data Protection dashboard like any other remote site you have created and configured. This feature is currently supported for ESXi hypervisor environments only.
Common Access Card Authentication
- You can configure two-factor authentication for web console users that have an assigned role and use a Common Access Card (CAC).
Default Container and Storage Pool Upon Cluster Creation
- When you create a cluster, the Acropolis base software automatically creates a container and storage pool for you.
Erasure Coding
- Complementary to deduplication and compression, erasure coding increases the effective or usable cluster storage capacity. [FEAT-1096]
Hyper-V Configuration through Prism Web Console
- After creating a Nutanix Hyper-V cluster environment, you can use the Prism web console to join the hosts to the domain, create the Hyper-V failover cluster, and also enable Kerberos.
Image Service Now Available in the Prism Web Console
- The Prism web console Image Configuration workflow enables a user to upload ISO or disk images (in ESXi or Hyper-V format) to a Nutanix AHV cluster by specifying a remote repository URL or by uploading a file from a local machine.
MPIO Access to iSCSI Disks (Windows Guest VMs)
- Acropolis base software 4.5 feature to help enforce access control to volume groups and expose volume group disks as dual namespace disks.
Network Mapping
- Network mapping allows you to control network configuration for the VMs when they are started on the remote site. This feature enables you to specify network mapping between the source cluster and the destination cluster. The remote site wizard includes an option to create one or more network mappings and allows you to select source and destination network from the drop-down list. You can also modify or remove network mappings as part of modifying the remote sites.
Nutanix Cluster Check
- Acropolis base software 4.5 includes Nutanix Cluster Check (NCC) 2.1, which includes many new checks and functionality.
- NCC 2.1 Release Notes
NX-6035C Clusters Usable as a Target for Replication
- You can use a Nutanix NX-6035C cluster as a target for Nutanix native replication and snapshots, created by source Nutanix clusters in your environment. You can configure the NX-6035C as a target for snapshots, set a longer retention policy than on the source cluster (for example), and restore snapshots to the source cluster as needed. The source cluster hypervisor environment can be AHV, Hyper-V, or ESXi. See Nutanix NX-6035C Replication Target in Notes and Cautions.
Note: You cannot use an NX-6035C cluster as a backup target with third-party backup software.
Prism Central Can Now Be Deployed on the Acropolis Hypervisor (AHV)
- Nutanix has introduced a Prism Central OVA which can be deployed on an AHV cluster by leveraging Image Service features. See the Web Console Guide for installation details.
- Prism Central 4.5 Release Notes
Prism Central Scalability
- By increasing memory capacity to 16GB and expanding its virtual disk to 260GB, Prism Central can support a maximum of 100 clusters and 10000 VMs (across all the clusters and assuming each VM has an average of two virtual disks). Please contact Nutanix support if you decide to change the configuration of the Prism Central VM.
- Prism Central 4.5 Release Notes
- Prism Central Scalability, Compatibility and Deployment
Simplified Add Node Workflow
- This release leverages Foundation 3.0 imaging capabilities and automates the manual steps previously required for expanding a cluster through the Prism web console.
SNMP
- The Nutanix SNMP MIB database includes the following changes:
- The database includes tables for monitoring hypervisor instances and virtual machines.
- The service status table named serviceStatusTable is obsolete. Analogous information is available in a new table named controllerStatusTable. The new table has a smaller number of MIB fields for displaying the status of only essential services in the Acropolis base software.
- The disk status table (diskStatusTable), storage pool table (storagePoolInformationTable), and cluster information table include one or more new MIB fields.
- The SNMP feature also includes the following enhancements:
- From the web console, you can trigger test alerts that are sent to all configured SNMP trap receivers.
- SNMP service logs are now written to the following log file: /home/nutanix/data/logs/snmp_manager.out
Support for Minor Release Upgrades for ESXi Hosts
- Acropolis base software 4.5 enables you to patch upgrade ESXi hosts with minor release versions of ESXi host software through the Controller VM cluster command. Nutanix qualifies specific VMware updates and provides a related JSON metadata upgrade file for one-click upgrade, but now customers can patch hosts by using the offline bundle and md5sum checksum available from VMware, and using the Controller VM cluster command.
Note: Nutanix supports the ability to patch upgrade ESXi hosts with minor versions that are greater than or released after the Nutanix qualified version, but Nutanix might not have qualified those minor releases. Please see the the Nutanix hypervisor support statement in our Support FAQ.
VM High Availability in Acropolis
- In case of a node failure, VM High Availability (VM-HA) ensures that VMs running on the node are automatically restarted on the remaining nodes within the cluster. VM-HA can optionally be configured to reserve spare failover capacity. This capacity reservation can be distributed across the nodes in chunks known as “segments” to provide better overall resource utilization.
Windows Guest VM Failover Clustering
- Acropolis base software 4.5 supports configuring Windows guest VMs as a failover cluster. This clustering type enables applications on a failed VM to fail over to and run on another guest VM on the same or different host. This release supports this feature on Hyper-V hosts with in-guest VM iSCSI and SCSI 3 Persistent Reservation (PR).
Tech Preview Features
Note: Do not use tech preview features on production systems or storage used or data stored on production systems.
File Level Restore
- The file level restore feature allows a virtual machine user to restore a file within a virtual machine from the Nutanix protected snapshot with minimal Nutanix administrator intervention.
Note: This feature should be used only after upgrading all nodes in the cluster to Acropolis base software 4.5.
What’s New in Prism Central
Prism Central for Acropolis Hypervisor (AHV)
Nutanix has introduced a Prism Central VM which is compatible with AHV to enable multicluster management in this environment. Prism Central now supports all three major hypervisors: AHV, Hyper-V, and ESXi.
Prism Central Scalability
The Prism Central VM requires these resources to support the clusters and VMs indicated in the table.
Prism Central vCPU | Prism Central Memory (GB, default) | Total Storage Required for Prism Central VM (GB) | Clusters Supported | VMs Supported (across all clusters) | Virtual disks per VM |
| 4 | 8 | 256 | 50 | 5000 | 2 |
Release Notes | NCC 2.1
Learn More About NCC Health Checks
You can learn more about the Nutanix Cluster Check (NCC) health checks on the Nutanix support portal. The portal includes a series of Knowledge Base articles describing most NCC health checks run by the ncc health_checks command.
What’s New in NCC 2.1
NCC 2.1 includes support for:
- Acropolis base software 4.5 or later
- NOS 4.1.3 or later only
- All Nutanix NX Series models
- Dell XC Series of Web-scale Converged Appliances
Tech Preview Features
The following features are available as a Tech Preview in NCC 2.1.
Run NCC health checks in parallel
- You can specify the number of NCC health checks to run in parallel to reduce the amount of time it takes for all checks to complete. For example, the command ncc health_checks run_all –parallel=25 will run 25 of the health checks in parallel.
Use npyscreen to display NCC status
- You can specify npyscreen as part of the ncc command to display status to the terminal window. Specify –npyscreen=true as part of the ncc health_checks command.
New Checks in This Release
| Check Name | Description | KB Article |
| check_disks | Check whether disks are discoverable by the host. Pass if the disks are discovered. | KB 2712 |
| check_pending_reboot | Check if host has pending reboots. Pass if host does not have pending reboots. | KB 2713 |
| check_storage_heavy_node | Verify that nodes such as the storage-heavy NX-6025C are running a service VM and no guest VMs.
Verify that nodes such as the storage-heavy NX-6025C are runningthe Acropolis hypervisor only. | KB 2726
KB 2727 |
| check_utc_clock | Check if UTC clock is enabled. | KB 2711 |
| cluster_version_check | Verifiy that the cluster is running a released version of NOS or the Acropolis base software. This check returns an INFO status and the version if the cluster is running a pre-release version. | KB 2720 |
| compression_disabled_check | Verify if compression is enabled. | KB 2725 |
| data_locality_check | Check if VMs that are part of a cluster with metro availability are in two different datastores (that is, fetching local data). | KB 2732 |
| dedup_and_compression_enabled_containers_check | Checks if any container have deduplication and compression enabled together. | KB 2721 |
| dimm_same_speed_check | Check that all DIMMs have the same speed. | KB 2723 |
| esxi_ivybridge_performance_degradation_check | Check for the Ivy Bridge performance degradation scenario on ESXi clusters. | KB 2729 |
| gpu_driver_installed_check | Check the version of the installed GPU driver. | KB 2714 |
| quad_nic_driver_version_check | Check the version of the installed quad port NIC driver version. | KB 2715 |
| vmknics_subnet_check | Check if any vmknics have same subnet (different subnets are not supported). | KB 2722 |
Foundation Release 3.0
This release includes the following enhancements and changes:
- A major new implementation that allows for node imaging and cluster creation through the Controller VM for factory-prepared nodes on the same subnet. This process significantly reduces network complications and simplifies the workflow. (The existing workflow remains for imaging bare metal nodes.) The new implementation includes the following enhancements:
- A Java aplet that automatically discovers factory-prepared nodes on the subnet and allows you to select the first one to image.
- A simplified GUI to select and configure the nodes, define the cluster, select the hypervisor and Acropolis base software versions to use, and monitor the imaging and cluster creation process.
Customers may create a cluster using the new Controller VM-based implementation in Foundation 3.0. Imaging bare metal nodes is still restricted to Nutanix sales engineers, support engineers, and partners.
- The new implementation is incorporated in the Acropolis base software version 4.5 to allow for node imaging when adding nodes to an existing cluster through the Prism GUI.
- The cluster creation workflow does not use IPMI, and for both cluster creation and bare-metal imaging, the host operating system install is done within an “installer VM” in Phoenix.
- To see the progress of a host operating system installation, point a VNC console at the node’s Controller VM IP address on port 5901.
- Foundation no longer offers the option to run diagnostics.py as a post-imaging test. Should you wish to run this test, you can download it from the Tools & Firmware page on the Nutanix support portal.
- There is no Foundation upgrade path to the new Controller VM implementation; you must download the Java aplet from the Foundation 3.0 download page on the support portal. However, you can upgrade Foundation 2.1.x to 3.0 for the bare metal workflow as follows:
- Copy the Foundation tarball (foundation-version#.tar.gz) from the support portal to /home/nutanix in your VM.
- Navigate to /home/nutanix.
- Enter the following five commands:
- $ sudo service foundation_service stop
- $ rm -rf foundation
- $ tar xzf foundation-version#.tar.gz
- $ sudo yum install python-scp
- $ sudo service foundation_service restart
- If the first command (foundation_service stop) is skipped or the commands are not run in order, the user may get bizarre errors after upgrading. To fix this situation, enter the following two commands:
- $ sudo pkill -9 foundation
- $ sudo service foundation_service restart
Release Notes for each of these products is located at:
- Acropolis base software 4.5: https://portal.nutanix.com/#/page/docs/details?targetId=Release_Notes-Acr_v4_5:rel_Release_Notes-Acr_v4_5.html
- Prism Central 4.5: https://portal.nutanix.com/#/page/docs/details?targetId=Release_Notes-Acr_v4_5:rel_Release_Notes-Prism_Central_v4_5.html
- Nutanix Cluster Check(NCC) 2.1: https://portal.nutanix.com/#/page/docs/details?targetId=Release_Notes-NCC:rel_Release_Notes-NCC_v2_1.html
- Foundation 3.0: https://portal.nutanix.com/#/page/docs/details?targetId=Field_Installation_Guide-v3_0:fie_release_notes_foundation_v3_0_r.html
Download URLs:
Until next time, Rob…


 Note if you only have two types of storage then the highest performing is used for the cache while the other type will be divided between performance and capacity with the different resiliency option (mirror vs parity) providing the performance/capacity difference between the tiers. If you only have one type of storage then the cache is disabled and the disks divided between performance and capacity like the previously mentioned case.
Note if you only have two types of storage then the highest performing is used for the cache while the other type will be divided between performance and capacity with the different resiliency option (mirror vs parity) providing the performance/capacity difference between the tiers. If you only have one type of storage then the cache is disabled and the disks divided between performance and capacity like the previously mentioned case.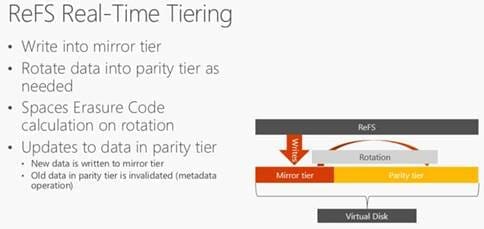

 During Ignite 2016, Microsoft took many shots at VMware. Microsoft said that there’s a right way and a wrong way to do erasure coding. “When you do it the wrong way, performance sucks and you have to limit it to all-flash configurations.”
During Ignite 2016, Microsoft took many shots at VMware. Microsoft said that there’s a right way and a wrong way to do erasure coding. “When you do it the wrong way, performance sucks and you have to limit it to all-flash configurations.”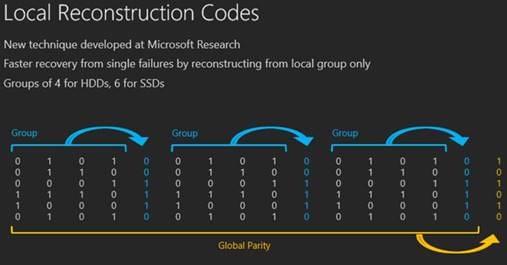 Ok, that’s all for now. next up, Fault Tolerance and Multisite Replication with S2D….
Ok, that’s all for now. next up, Fault Tolerance and Multisite Replication with S2D….