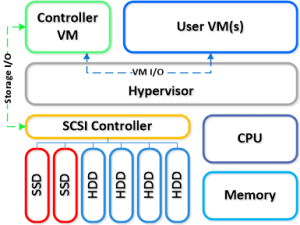
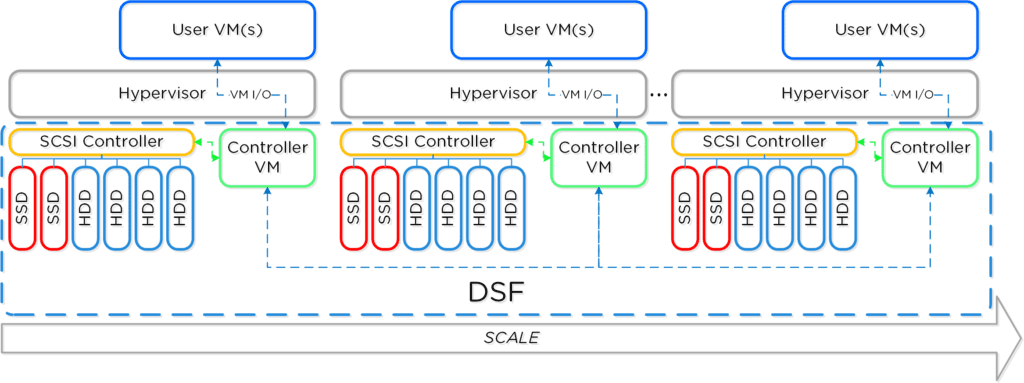
To continue NPP training series here is my next topic: Cluster Components
If you missed other parts of my series, check out links below:
Part 1 – NPP Training series – Nutanix Terminology
Part 2 – NPP Training series – Nutanix Terminology
Cluster Architecture with Hyper-V
Data Structure on Nutanix with Hyper-V
I/O Path Overview
To give credit, most of the content was taken from Steve Poitras’s “Nutanix Bible” blog as his content is the most accurate and then I put a Hyper-V lean to it.
Cluster Components
The Nutanix platform is composed of the following high-level components:
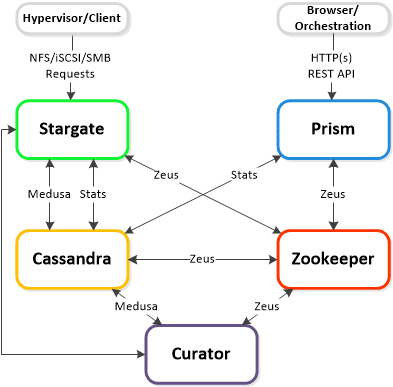
Cassandra
- Key Role: Distributed metadata store
- Description: Cassandra stores and manages all of the cluster metadata in a distributed ring like manner based upon a heavily modified Apache Cassandra. The Paxos algorithm is utilized to enforce strict consistency. This service runs on every node in the cluster. Cassandra is accessed via an interface called Medusa.
Medusa
- Key Role: Abstraction layer
- Description: Medusa is the Nutanix abstraction layer that sits in front of the cluster’s distributed metadata database, which is managed by Cassandra..
Zookeeper
- Key Role: Cluster configuration manager
- Description: Zeus stores all of the cluster configuration including hosts, IPs, state, etc. and is based upon Apache Zookeeper. This service runs on three nodes in the cluster, one of which is elected as a leader. The leader receives all requests and forwards them to the peers. If the leader fails to respond a new leader is automatically elected. Zookeeper is accessed via an interface called Zeus.
Zeus
- Key Role: Library interface
- Description: Zeus is the Nutanix library interface that all other components use to access the cluster configuration, such as IP addresses. Currently implemented using Zookeeper, Zeus is responsible for critical, cluster-wide data such as cluster configuration and leadership locks.
Stargate
- Key Role: Data I/O manager
- Description: Stargate is responsible for all data management and I/O operations and is the main interface from Hyper-V (via SMB 3.0). This service runs on every node in the cluster in order to serve localized I/O.
Curator
- Key Role: Map reduce cluster management and cleanup
- Description: Curator is responsible for managing and distributing tasks throughout the cluster including disk balancing, proactive scrubbing, and many more items. Curator runs on every node and is controlled by an elected Curator Master who is responsible for the task and job delegation. There are two scan types for Curator, a full scan which occurs around every 6 hours and a partial scan which occurs every hour.
Prism
- Key Role: UI and API
- Description: Prism is the management gateway for component and administrators to configure and monitor the Nutanix cluster. This includes Ncli, the HTML5 UI and REST API. Prism runs on every node in the cluster and uses an elected leader like all components in the cluster.
Genesis
- Key Role: Cluster component & service manager
- Description: Genesis is a process which runs on each node and is responsible for any services interactions (start/stop/etc.) as well as for the initial configuration. Genesis is a process which runs independently of the cluster and does not require the cluster to be configured/running. The only requirement for genesis to be running is that Zookeeper is up and running. The cluster_init and cluster_status pages are displayed by the genesis process.
Chronos
- Key Role: Job and Task scheduler
- Description: Chronos is responsible for taking the jobs and tasks resulting from a Curator scan and scheduling/throttling tasks among nodes. Chronos runs on every node and is controlled by an elected Chronos Master who is responsible for the task and job delegation and runs on the same node as the Curator Master.
Cerebro
- Key Role: Replication/DR manager
- Description: Cerebro is responsible for the replication and DR capabilities of DFS(Distributed Storage Fabric). This includes the scheduling of snapshots, the replication to remote sites, and the site migration/failover. Cerebro runs on every node in the Nutanix cluster and all nodes participate in replication to remote clusters/sites.
Pithos
- Key Role: vDisk configuration manager
- Description: Pithos is responsible for vDisk (DFS file) configuration data. Pithos runs on every node and is built on top of Cassandra.
Next up, Data Structures which comprises high level structs for Nutanix Distributed Filesystem
Until next time, Rob….