To continue the Windows Azure Pack series, here is my next topic: Windows Azure Pack – Environment Prep
If you missed parts 1 or 2 in the series, check links below:
Part 1 – Understanding Windows Azure Pack
Part 2 – Understanding Windows Azure Pack – Deployment Scenarios
Environment Prep
In the first blog posting in this series we examined the capabilities and benefits of deploying WAP (Windows Azure Pack) in enterprise datacenters by first looking at Windows Azure, Microsoft’s public cloud offering.
In the second blog posting we looked at some of the terminology associated with WAP and we summarized two kinds of deployment scenarios on Nutanix: Express and Distributed architecture
Moving on…”Cloud” is the buzz word in all aspects of our computing life today, and more and more companies want to be able to offer the benefits of a “Cloud” environment to their on premises users. And by now, we should all know the Public Cloud (i.e. Azure, Amazon, etc.) might not suit everyone and is definitely not suited for all situations….That is where Nutanix and WAP standout;
Giving your the ability to have a predictable, scalable , highly available, high performing IaaS (Infrastructure as a Service) hybrid datacenter
This series is meant to be a guide to building your own WAP test lab on Nutanix and also provide you guidance for building out a production Nutanix WAP environment.
WAP Test Environment Requirements
Just to see functionally, you could deploy it the requirements on one host with Nutanix CE (Community Edition), but building this WAP environment on a Nutanix cluster will give you real world results.
In this series, we will be building 2 VM’s for the WAP test environment. The VM’s consist of SPF (Service Provider Foundation) Server and Windows Azure Pack Server.
In my test lab, I am using a 4 Node Nutanix NX3050 Cluster with Server 2012 R2 Hyper-V. This blog post assumes you have an Active Directory Domain and SCVMM (System Center Virtual Machine Manager) 2012 R2 up and running. It also assumes you have an empty SQL 2012 SP1 server built for hosting SPF, WAP and Tenant SQL Databases.
In this Post:
WAP Pre-requisites:
Virtual Machine Manager is installed and configured and:
- Member of the Active Directory domain.
- One or more SCVMM Clouds created in SCVMM (see below video)
- One or more VM Networks created in SCVMM (see below video)
Service Provider Foundation
- Windows Server 2012 R2
- 4 Gigs of RAM
- 2 CPU Cores
- Database Storage
- Member of the Active Directory domain
- Windows Azure Pack Server
- Windows Server 2012 R2
- 4 Gigs of RAM
- 2 CPU cores
- 20 Gigs Data Storage
- Database Storage
- Member of the Active Directory domain
SQL Server is installed and running
- Windows Server 2012 R2
- SP1 or Above
- 16 Gigs of RAM
- 2 CPU Cores
- 100 Gigs Data and Log Drive
- With Mixed or SQL Authentication enabled
- Member of the Active Directory domain
If you need help building a SCVMM 2012 R2 Server, check out my blog post on Installing SCVMM 2012 R2 on Nutanix (coming soon).
If you need help building a SQL 2012 Server, check out my blog post on Install SQL 2012 on Nutanix (coming soon)
If you need help deploying Hyper-V to a Nutanix cluster and joining the cluster to an Active Directory Domain, see my buddy Chris Brown’s Blog Video on Installing Hyper-V on Nutanix. This also covers adding it to SCVMM 2012 R2. He also has a great Hyper-VSCVMM Networking Overview. Another great NutanixMicrosoft resource.
Installing Hyper-V on Nutanix
Hyper-V Networking Overview
SCVMM Server / Fabric Prep
Account requirements
The Active Directory security account groups below are recommended as best practices when deploying WAP with SCVMM. Active Directory Security were created and mapped in SCVMM as Delegated Administrations. See screenshots below.
Self-Service Users (tenants) storage of VMs in the SCVMM Library
You will also need to create a library share, or create a folder in a library share that will serve as the storage location for tenants. Also, understanding that self-service users must have the Store and Re-Deploy permission to store their virtual machines in important. In my test lab, I created a Nutanix container (SMB Share) with compression attributes and presented it to SCVMM.
IMPORTANT RULES FOR LIBRARY SHARES
- The library share location that you designate for stored virtual machines must be different from the shares that you designate as read-only resource locations for the private cloud.
- The path or part of the path must be unique when compared to the user role data path that is specified for a self-service user role
- You could also create entirely separate library shares with containers on Nutanix,like I did above
- Understand that you will configure the stored virtual machine path and read-only library shares when you run the Create Cloud Wizard as shown video below.
- The self-service user role data path is specified when you create a self-service user role or modify the properties of a self-service user role.
- Make sure that one or more library shares exists that you can assign as the read-only library shares for self-service users to use.
- The library shares that you designate as read-only resource locations for the private cloud must be unique when compared to the library share or shares that are used for stored virtual machines and for the user role data path that is specified for a self service user role.
Creating Tenant Storage and Private Cloud in SCVMM 2012 R2 on Nutanix
In high level, best practices is to have each tenant how their own separate storage containers as shown in below diagram. This will allow you to advertise available capacity, security boundaries, and apply attributes, like deduplication or compression on a per container basis and then tie it up to storage classifications in SCVMM.
Next is to create storage for you tenants. In Prism, create a new container with the name of your tenant, set an advertised capacity and add any storage attributes, like deduplication or compression depending on the type of workloads being hosted. See the below a video I produced with my buddy @Mike TME at Nutanix of the process:
If you have any questions about the prep, please comment below.
Yea, now we can finally deploy the WAP. Now the fun part starts…..
Next up in my series, Installing the Windows Azure Pack environment on Nutanix – Deploying SPF (Service Provider Foundation)

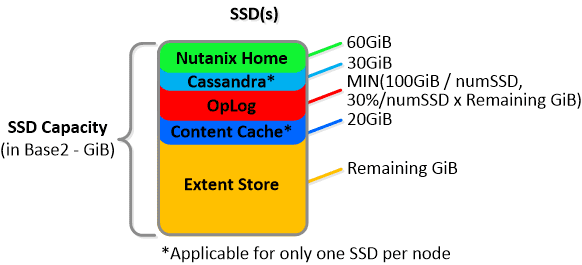
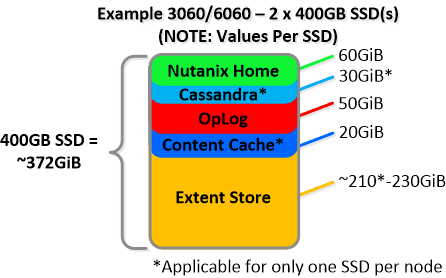
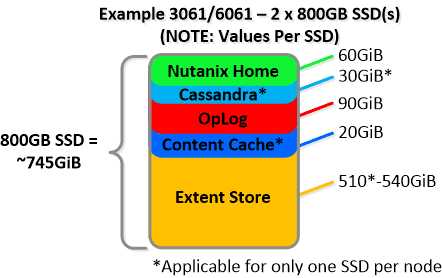
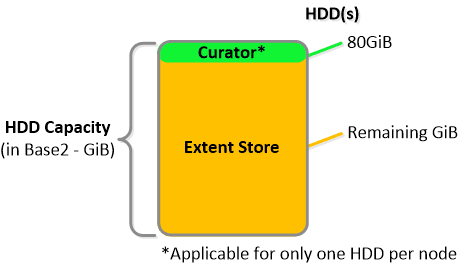
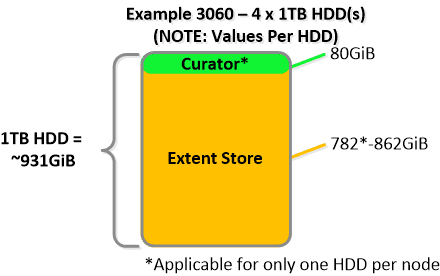

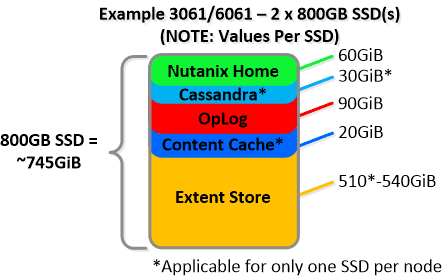
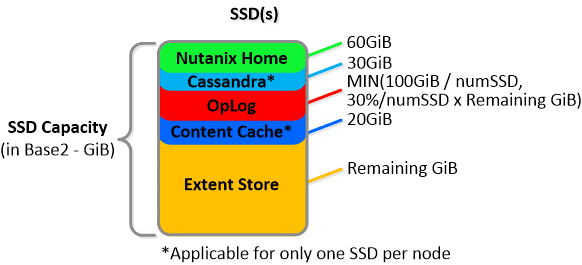 NOTE: The sizing for OpLog is done dynamically as of release 4.0.1 which will allow the extent store portion to grow dynamically. The values used are assuming a completely utilized OpLog. Graphics and proportions aren’t drawn to scale. When evaluating the Remaining GiB capacities do so from the top down.
NOTE: The sizing for OpLog is done dynamically as of release 4.0.1 which will allow the extent store portion to grow dynamically. The values used are assuming a completely utilized OpLog. Graphics and proportions aren’t drawn to scale. When evaluating the Remaining GiB capacities do so from the top down.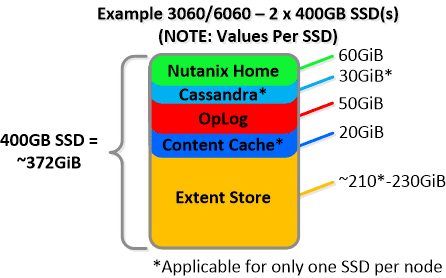
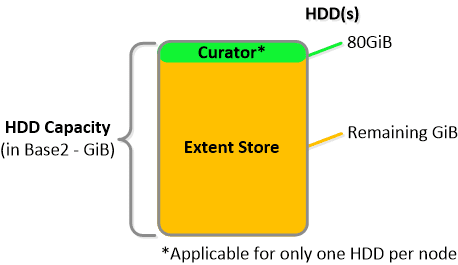
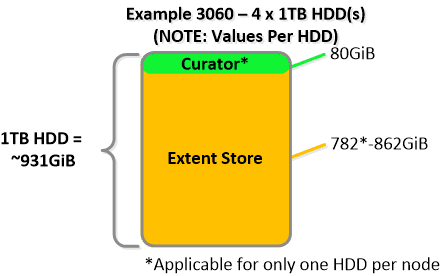 For a 6060 node which has 4 x 4TB HDDs this would give us 80GiB reserved for Curator and ~14TiB of Extent Store HDD capacity per node.
For a 6060 node which has 4 x 4TB HDDs this would give us 80GiB reserved for Curator and ~14TiB of Extent Store HDD capacity per node.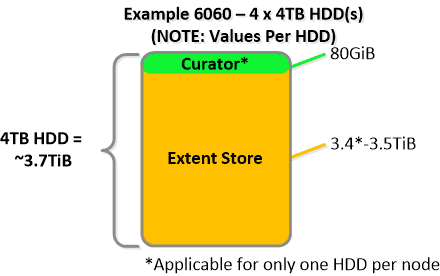 Statistics and technical specifications:
Statistics and technical specifications: 
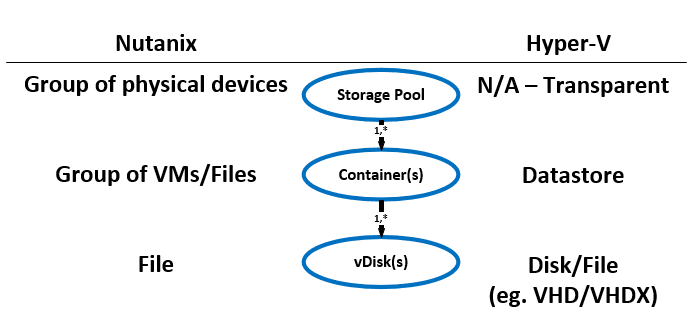
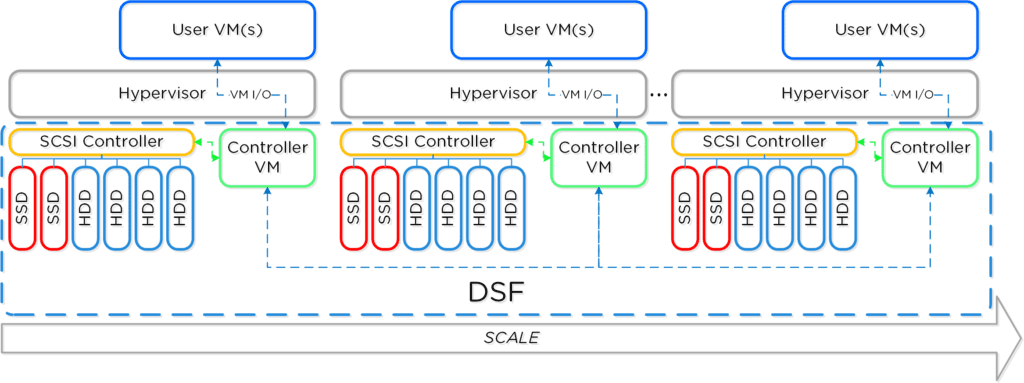
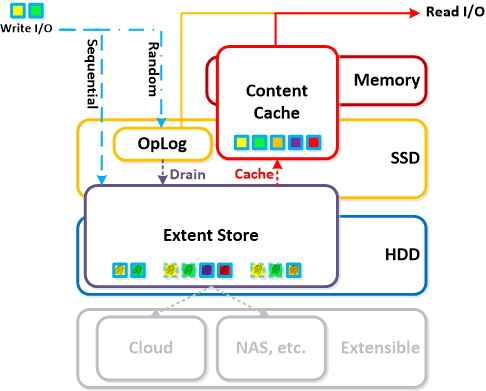
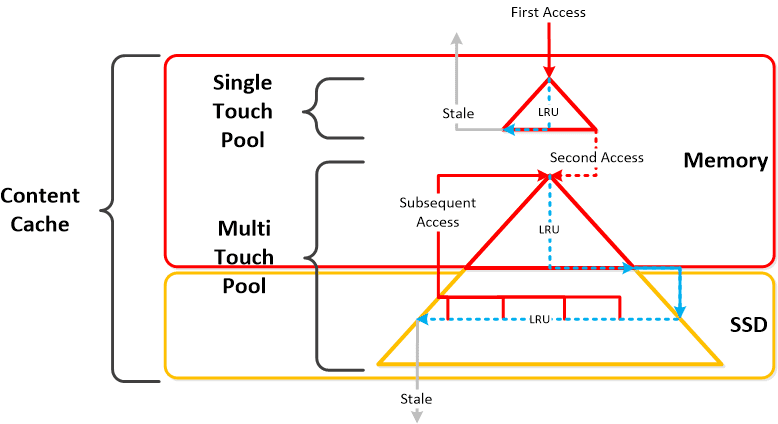
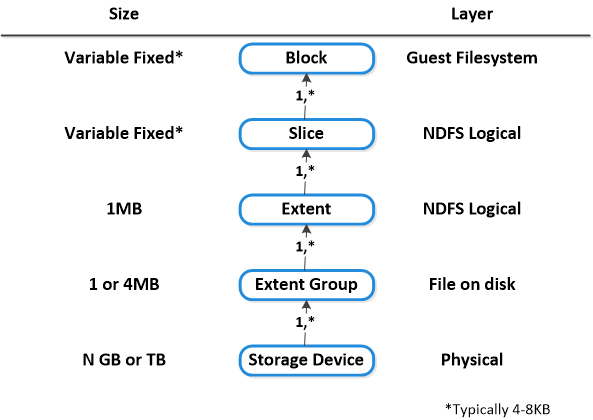 Here is another graphical representation of how these units are logically related:
Here is another graphical representation of how these units are logically related: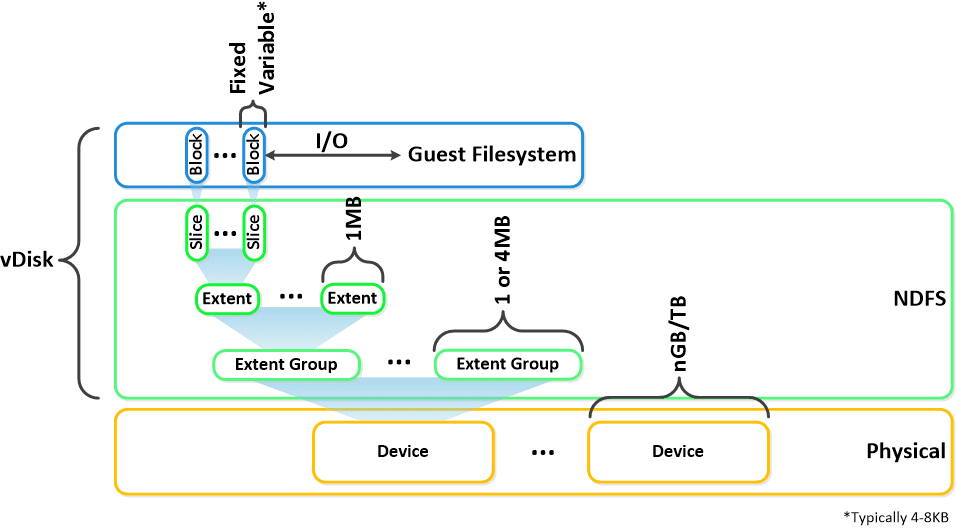 Next up,
Next up,