To give credit, this content was taken from my buddy Mike McGhem’s blog and I added some more color to it, but his content is right on.
Microsoft SQL Server High Availability Options on Nutanix
Reply

To give credit, this content was taken from my buddy Mike McGhem’s blog and I added some more color to it, but his content is right on.
As a Microsoft Solutions Architect, part of my job is to help the teams with solutions around the Microsoft stack. Today, a colleague of mine reached out to me about the new SQL Server AlwaysOn feature that part of SQL 2012 and how it compared to SQL 2008 clustering….So I started with this topic to bring some understanding around it:
SQL Server AlwaysON
Prior to SQL Server 2012, SQL Server had several high availability and disaster recovery solutions for an enterprise’s mission critical databases such as failover clustering, database mirroring, log shipping or combinations of these. Each solution typically has a major limitation, in the case of failover clustering for example, its configuration is very tedious and complex and you arguably have single shared storage or single point of failure.
Database mirroring is relatively easy to configure in comparison with failover clustering, but you can have only one database in a single mirroring setup and you cannot read from the mirrored database. Log shipping does not provide automatic failover (higher availability) though it be used for disaster recovery with some expected data loss.
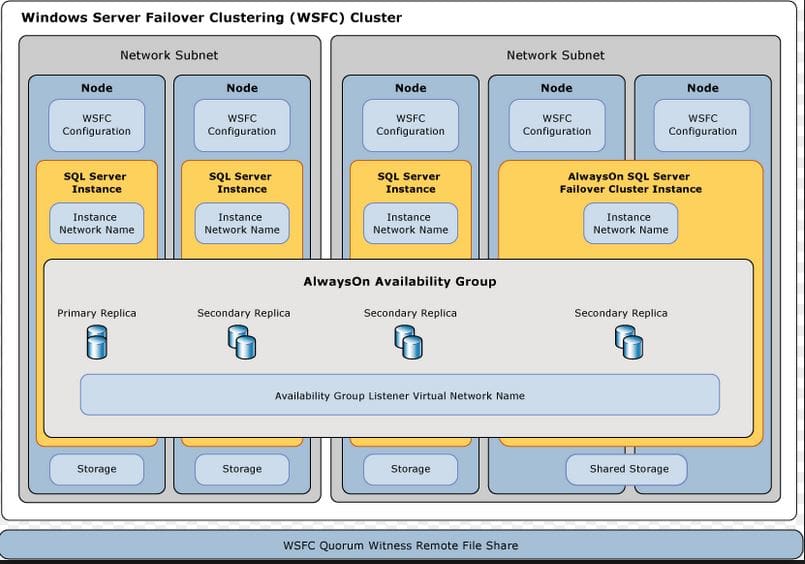
SQL 2012 AlwaysOn Diagram
SQL Server 2012 introduced a new feature called AlwaysOn which combines the best of failover clustering and database mirroring and overcomes major of the limitations imposed in failover clustering or a database mirroring setup.
AlwaysOn is a High Availability (HA) and Disaster Recovery (DR) solution in SQL Server 2012 which improves high availability and protects data of your mission critical applications. AlwaysOn is the common name for two high availability and disaster recovery solutions:
AlwaysOn Failover Cluster Instance (FCI)
This is an enhancement to the existing SQL Server failover clustering (which is based on Windows Server Failover Cluster (WSFC)) which provides higher availability of SQL Server instance after failover. Some of the enhancements in AlwaysOn Failover Cluster Instance over the existing SQL Server failover clustering are:
AlwaysOn Availability Group (AG)
This is a new HA/DR feature in SQL 2012 and combines best of failover clustering and database mirroring. It allows you to create a group of databases which failover together as a unit from one replica/instance of SQL Server to another replica/instance of SQL Server in the same availability group. Each availability group that we create, allows you to create one (and only) availability group listener which is nothing but a Virtual Network Name (VNN) to be used by clients to connect to the availability group.
The AlwaysOn availability group is based on Windows Server Failover Cluster (WSFC) and hence you need to install the failover clustering feature on each server/replica and create a failover cluster adding all these server/replicas before you can start enabling/creating the availability group.
Availability Groups Compared To Traditional SQL Server Failover Clustering
In a typical SQL Server failover cluster (at the instance level), you will have two nodes/instances (Active-Passive or Active-Active) connected to shared storage drives. Though SQL Server failover clustering has been good and is used in many deployments for higher availability and disaster recovery, it has several limitations and pain points, such as:
How Availability Group differs from database mirroring
Database mirroring (at database level) can be set up in either synchronous mode or asynchronous mode but not both in a single mirroring setup.
These all sound like good solutions, but like SQL Server failover clustering, it has also several limitations:
An AlwaysOn availability group is recommended over database mirroring as this overcomes several limitations imposed in database mirroring, for example with an AlwaysOn availability group:
So…as you can see….it is a welcomed feature in SQL Clustering technologies. It reminds me a lot of the Exchange Available Groups for DB introduced in Exchange 2010. There are some new upcoming features being announced for SQL AlwaysON at Ignite from what I hear. Do we have SQL Azure integration coming?
Until next time, Rob…