As a Microsoft Solutions Architect, part of my job is to help the teams with solutions around the Microsoft stack. Today, a colleague of mine reached out to me about the new SQL Server AlwaysOn feature that part of SQL 2012 and how it compared to SQL 2008 clustering….So I started with this topic to bring some understanding around it:
SQL Server AlwaysON
Prior to SQL Server 2012, SQL Server had several high availability and disaster recovery solutions for an enterprise’s mission critical databases such as failover clustering, database mirroring, log shipping or combinations of these. Each solution typically has a major limitation, in the case of failover clustering for example, its configuration is very tedious and complex and you arguably have single shared storage or single point of failure.
Database mirroring is relatively easy to configure in comparison with failover clustering, but you can have only one database in a single mirroring setup and you cannot read from the mirrored database. Log shipping does not provide automatic failover (higher availability) though it be used for disaster recovery with some expected data loss.

SQL 2012 AlwaysOn Diagram
SQL Server 2012 introduced a new feature called AlwaysOn which combines the best of failover clustering and database mirroring and overcomes major of the limitations imposed in failover clustering or a database mirroring setup.
AlwaysOn is a High Availability (HA) and Disaster Recovery (DR) solution in SQL Server 2012 which improves high availability and protects data of your mission critical applications. AlwaysOn is the common name for two high availability and disaster recovery solutions:
AlwaysOn Failover Cluster Instance (FCI)
This is an enhancement to the existing SQL Server failover clustering (which is based on Windows Server Failover Cluster (WSFC)) which provides higher availability of SQL Server instance after failover. Some of the enhancements in AlwaysOn Failover Cluster Instance over the existing SQL Server failover clustering are:
- Multisite failover clustering
- Flexible failover policies to better control instance failover
- Improved diagnostics capabilities out of the box
AlwaysOn Availability Group (AG)
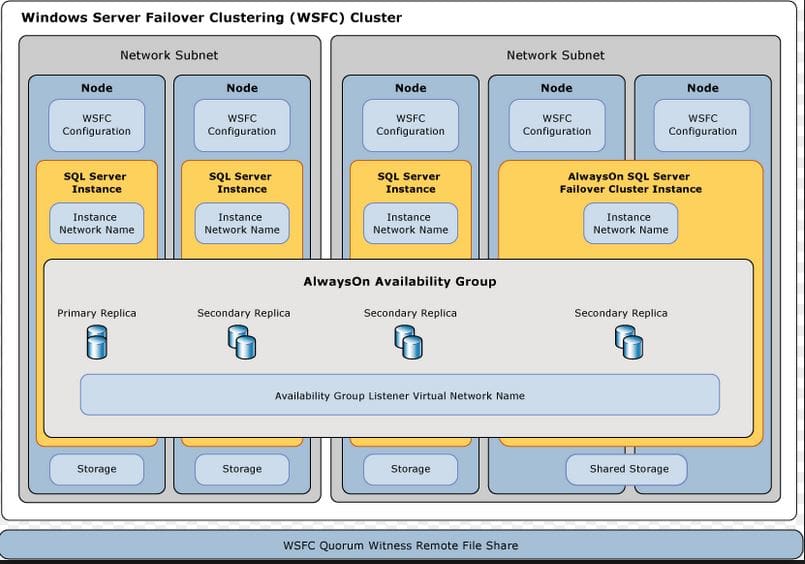
This is a new HA/DR feature in SQL 2012 and combines best of failover clustering and database mirroring. It allows you to create a group of databases which failover together as a unit from one replica/instance of SQL Server to another replica/instance of SQL Server in the same availability group. Each availability group that we create, allows you to create one (and only) availability group listener which is nothing but a Virtual Network Name (VNN) to be used by clients to connect to the availability group.
The AlwaysOn availability group is based on Windows Server Failover Cluster (WSFC) and hence you need to install the failover clustering feature on each server/replica and create a failover cluster adding all these server/replicas before you can start enabling/creating the availability group.
Availability Groups Compared To Traditional SQL Server Failover Clustering
In a typical SQL Server failover cluster (at the instance level), you will have two nodes/instances (Active-Passive or Active-Active) connected to shared storage drives. Though SQL Server failover clustering has been good and is used in many deployments for higher availability and disaster recovery, it has several limitations and pain points, such as:
- The process of setting up SQL Server failover clustering is tedious and complex – there are some 30-40 steps that you have to perform missing any of those steps can result in hours of additional work. This is why setting up SQL Server failover clustering is only recommended to be performed by highly experienced professionals.
- Both the nodes are connected to a shared storage drive; though these drives might have their own failover mechanisms we still can have a single point of failure.
One of the nodes is idle all the time in case of Active-Passive cluster (recommended) and hence resources are underutilized. Though you have an Active-Active failover cluster this is not recommended as after failover one node will have double the load from both the cluster setup/applications.
- The infrastructure and configuration of each node should be exactly same as other nodes and mimic each other.
- You cannot distribute or load balance your read-write load from read only load on multiple nodes.
- An AlwaysOn availability group is superior to SQL Server failover clustering because the configuration, deployment and management is relatively simple and all the nodes/replicas will a copy of the databases and hence there is no shared storage or a single point of failure. You can have readable secondary and hence you can route your read-only load to a secondary replica and the read-write load to primary replica and hence have better utilization of your hardware resources.
How Availability Group differs from database mirroring
Database mirroring (at database level) can be set up in either synchronous mode or asynchronous mode but not both in a single mirroring setup.
- Synchronous Commit mode (high-safety) : The transaction logs are hardened at both the principal server as well as at the mirror server before commit acknowledgement is returned to the client; it may introduce some latency but ensures no data loss after failover. In this mode you can also set automatic failover and for that you need another instance which will work as a witness and performs the job of role switching.
- Asynchronous Commit mode (high performance) : The principal server hardens the transaction log at the principal server and returns the commit acknowledgement to client without waiting for transaction log hardening acknowledgement to be received from the mirror server. Transaction log hardening at the mirror server happens in an asynchronous manner.
These all sound like good solutions, but like SQL Server failover clustering, it has also several limitations:
- You can have only one database in a single mirroring session/setup, though you can define multiple mirroring sessions/setups (one for each database) but it is not possible to have a group of databases failover together.
- Databases on mirror server are always in recovery mode and hence you cannot read from a mirrored database (though you can create a database snapshot and read from it but but would only reflect data till the particular point in time when it was created).
- You cannot load balance your read-write requests on one server and read-only on another server.
- You can have only one mirror server; you cannot have one for higher availability (synchronous commit mode) and one for disaster recovery (asynchronous commit mode) in one single mirroring session, although you can combine it with log shipping for disaster recovery.
An AlwaysOn availability group is recommended over database mirroring as this overcomes several limitations imposed in database mirroring, for example with an AlwaysOn availability group:
- You can have multiple mirrored instance/nodes/replicas (up to four secondaries apart from one primary replica) with a combination of synchronous commit mode and asynchronous commit mode both at the same time. The replica set up in synchronous commit mode can be used for higher availability (or for automatic failover) and the replica set up in asynchronous commit mode can be used for disaster recovery.
- You can combine two or more database together and failover them as a unit, you don’t need to do it for each database separately as you were doing in case of database mirroring.
- You can offload the read-only load from the primary replica to the secondary by configuring the secondary as readable. In this way you can have better utilization of secondary replica’s hardware resources.
- You can also offload backup operations from the primary replica to the secondary replica and hence have less workload/IO on the primary replica and better utilization of the secondary replica’s hardware.
So…as you can see….it is a welcomed feature in SQL Clustering technologies. It reminds me a lot of the Exchange Available Groups for DB introduced in Exchange 2010. There are some new upcoming features being announced for SQL AlwaysON at Ignite from what I hear. Do we have SQL Azure integration coming?
Until next time, Rob…