Yo everyone…This is going to be a short blog post in this series. I am just covering Networking and Storage QoS as it pertains to S2D. There are the technologies the bind S2D together.
Storage QoS
S2D is using the Storage (QoS) Quality of Service that ships with Windows Server 2016 which provides standard min/max IOPS and bandwidth control. QoS policy can be applied at the VHD, VM, Groups of VMs, or Tenant Level. Benefits include:
- Mitigate noisy neighbor issues. By default, Storage QoS ensures that a single virtual machine cannot consume all storage resources and starve other virtual machines of storage bandwidth.
- Monitor end to end storage performance. As soon as virtual machines stored on a Scale-Out File Server are started, their performance is monitored. Performance details of all running virtual machines and the configuration of the Scale-Out File Server cluster can be viewed from a single location
- Manage Storage I/O per workload business needs Storage QoS policies define performance minimums and maximums for virtual machines and ensures that they are met. This provides consistent performance to virtual machines, even in dense and overprovisioned environments. If policies cannot be met, alerts are available to track when VMs are out of policy or have invalid policies assigned.
 What’s New in Networking with S2D?
What’s New in Networking with S2D?
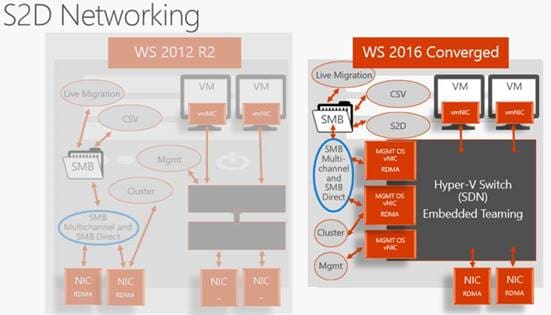
In Windows Server 2016, they added Remote Direct Memory Access (RDMA) support to the Hyper-V virtual switch.
For those that don’t know what RMDA is it technology that allows direct memory access from one computer to another, bypassing TCP layer, CPU , OS layer and driver layer. Allowing for low latency and high-throughput connections. This is done with hardware transport offloads on network adapters that support RDMA.
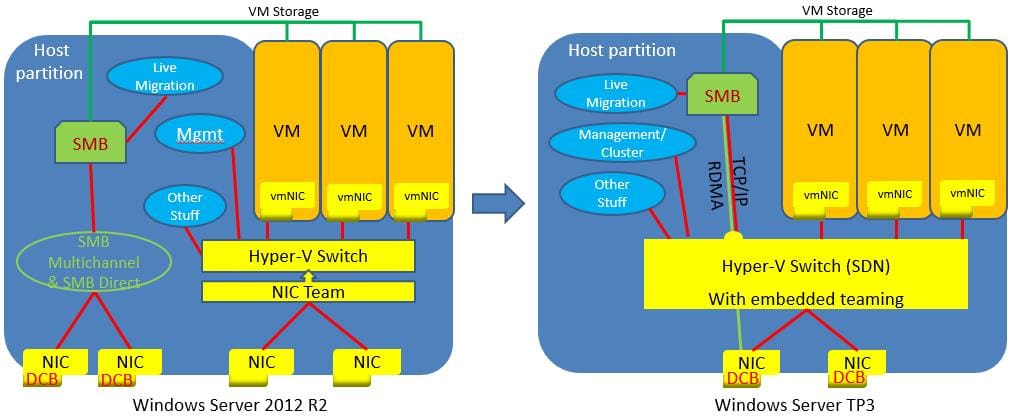
Back to Hyper-V virtual switch support for RDMA. This allows you to configure regular or RDMA enabled vNICs on top of a pair of RDMA capable physical NICs. They also added embedded NIC teaming or Switch Embedded Teaming (SET).
SET is where NIC teaming and the Hyper-V switch is a single entity and can now be used in conjunction with RDMA NICs, wherein Windows 2012 Server you needed to have separate NIC teams for RDMA and Hyper-V Switch.
The images below illustrates the architecture changes between Windows Server 2012 R2 and Windows Server 2016.
 Next up…Management and Operations…
Next up…Management and Operations…
Until next time, Rob