
Estimated reading time: 5 minutes
 Thank you for reading this post, don't forget to subscribe! Happy New Year 2024!
Thank you for reading this post, don't forget to subscribe! Happy New Year 2024!
To continue NPP training series, here is my next topic: I/O Path Overview
If you missed other parts of my series, check out links below:
Part 1 – NPP Training series – Nutanix Terminology
Part 2 – NPP Training series – Nutanix Terminology
Cluster Architecture with Hyper-V
Data Structure on Nutanix with Hyper-V
To give credit, most of the content was taken from Steve Poitras’s “Nutanix Bible” blog as his content is the most accurate and then I put a Hyper-V lean-to it.
IO Path Overview
The Nutanix IO path is composed of the following high-level components:
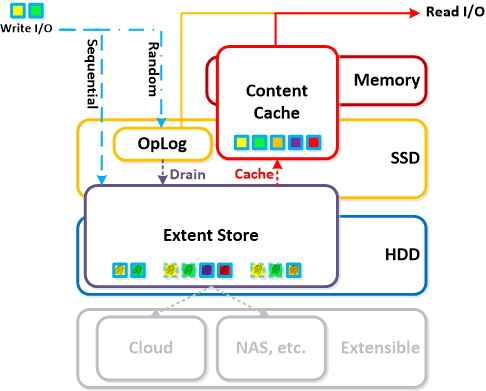
OpLog
- Key Role: Persistent write buffer
- Description: The Oplog is similar to a filesystem journal and is built to handle bursty writes, coalesce them and then sequentially drain the data to the extent store. Upon a write the OpLog is synchronously replicated to another n number of CVM’s OpLog before the write is acknowledged for data availability purposes. All CVM OpLogs partake in the replication and are dynamically chosen based upon load. The OpLog is stored on the SSD tier on the CVM to provide extremely fast write I/O performance, especially for random I/O workloads. For sequential workloads the OpLog is bypassed and the writes go directly to the extent store. If data is currently sitting in the OpLog and has not been drained, all read requests will be directly fulfilled from the OpLog until they have been drain where they would then be served by the extent store/content cache. For containers where fingerprinting (aka Dedupe) has been enabled, all write I/Os will be fingerprinted using a hashing scheme allowing them to be deduped based upon fingerprint in the content cache.
Extent Store
- Key Role: Persistent data storage
- Description: The Extent Store is the persistent bulk storage of NDFS and spans SSD and HDD and is extensible to facilitate additional devices/tiers. Data entering the extent store is either being A) drained from the OpLog or B) is sequential in nature and has bypassed the OpLog directly. Nutanix ILM will determine tier placement dynamically based upon I/O patterns and will move data between tiers.
Content Cache
- Key Role: Dynamic read cache
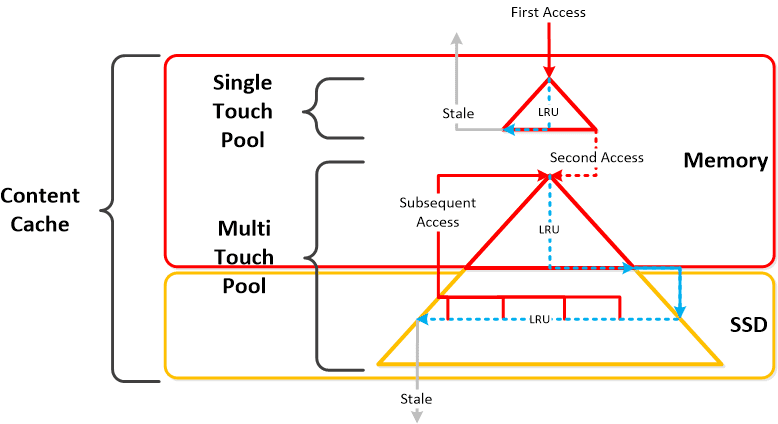
- Description: The Content Cache (aka “Elastic Dedupe Engine”) is a deduped read cache which spans both the CVM’s memory and SSD. Upon a read request of data not in the cache (or based upon a particular fingerprint) the data will be placed in to the single-touch pool of the content cache which completely sits in memory where it will use LRU until it is ejected from the cache. Any subsequent read request will “move” (no data is actually moved, just cache metadata) the data into the memory portion of the multi-touch pool which consists of both memory and SSD. From here there are two LRU cycles, one for the in-memory piece upon which eviction will move the data to the SSD section of the multi-touch pool where a new LRU counter is assigned. Any read request for data in the multi-touch pool will cause the data to go to the peak of the multi-touch pool where it will be given a new LRU counter. Fingerprinting is configured at the container level and can be configured via the UI. By default fingerprinting is disabled.
- Below we show a high-level overview of the Content Cache:
Extent Cache
- Key Role: In-memory read cache
- Description: The Extent Cache is an in-memory read cache that is completely in the CVM’s memory. This will store non-fingerprinted extents for containers where fingerprinting and dedupe disabled.
Drive Breakdown
In this section I’ll cover how the various storage devices (SSD / HDD) are broken down, partitioned and utilized by the Nutanix platform. NOTE: All of the capacities used are in Base2 Gibibyte (GiB) instead of the Base10 Gigabyte (GB). Formatting of the drives with a filesystem and associated overheads has also been taken into account.
SSD Devices
SSD devices store a few key items which are explained in greater detail above:
- Nutanix Home (CVM core)
- Cassandra (metadata storage) – MORE
- OpLog (persistent write buffer)
- Extent Store (persistent storage)
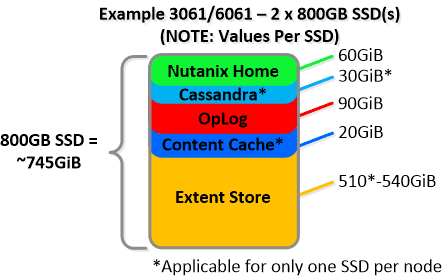
Below we show an example of the storage breakdown for a Nutanix node’s SSD(s):
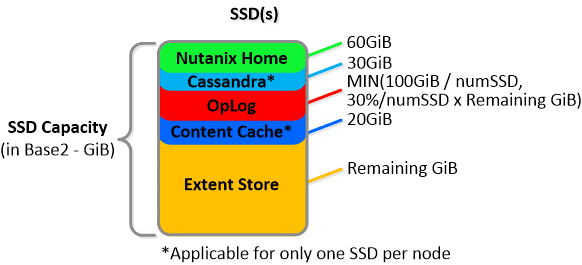 NOTE: The sizing for OpLog is done dynamically as of release 4.0.1 which will allow the extent store portion to grow dynamically. The values used are assuming a completely utilized OpLog. Graphics and proportions aren’t drawn to scale. When evaluating the Remaining GiB capacities do so from the top down.
NOTE: The sizing for OpLog is done dynamically as of release 4.0.1 which will allow the extent store portion to grow dynamically. The values used are assuming a completely utilized OpLog. Graphics and proportions aren’t drawn to scale. When evaluating the Remaining GiB capacities do so from the top down.
For example the Remaining GiB to be used for the OpLog calculation would be after Nutanix Home and Cassandra have been subtracted from the formatted SSD capacity. Most models ship with 1 or 2 SSDs, however the same construct applies for models shipping with more SSD devices. For example, if we apply this to an example 3060 or 6060 node which has 2 x 400GB SSDs this would give us 100GiB of OpLog, 40GiB of Content Cache and ~440GiB of Extent Store SSD capacity per node. Storage for Cassandra is a minimum reservation and may be larger depending on the quantity of data.
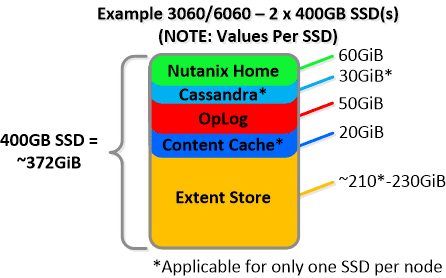
For a 3061 node which has 2 x 800GB SSDs this would give us 100GiB of OpLog, 40GiB of Content Cache and ~1.1TiB of Extent Store SSD capacity per node.
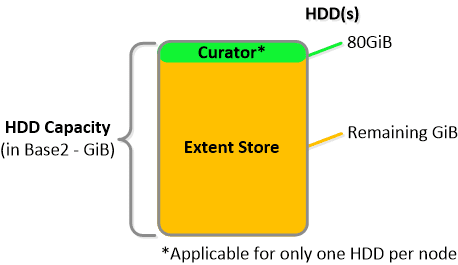
HDD Devices
Since HDD devices are primarily used for bulk storage, their breakdown is much simpler:
- Curator Reservation (Curator storage) – MORE
- Extent Store (persistent storage)
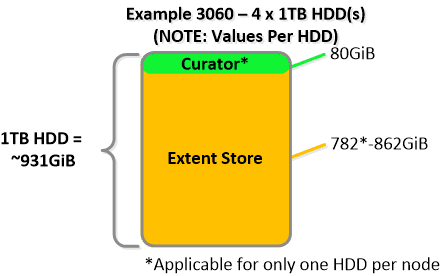
For example, if we apply this to an example 3060 node which has 4 x 1TB HDDs this would give us 80GiB reserved for Curator and ~3.4TiB of Extent Store HDD capacity per node.
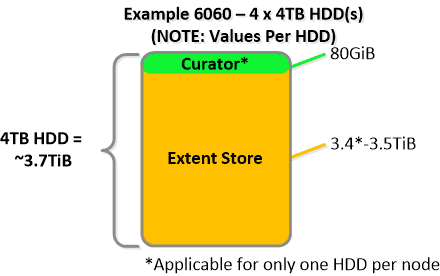
 For a 6060 node which has 4 x 4TB HDDs this would give us 80GiB reserved for Curator and ~14TiB of Extent Store HDD capacity per node.
For a 6060 node which has 4 x 4TB HDDs this would give us 80GiB reserved for Curator and ~14TiB of Extent Store HDD capacity per node.
 Statistics and technical specifications: opportunites-digitales.com/avis-expressvpn/
Statistics and technical specifications: opportunites-digitales.com/avis-expressvpn/
NOTE: the above values are accurate as of 4.0.1 and may vary by release.
Next up, Drive Breakdown on Nutanix
Until next time, Rob….