Here’s where we dive in and get dirty…but I promise by the end of my series, you will smiling like my friend here. I am planning a surprise with special guest bloggers. Stayed Tuned. Now one to the show…..

The NEW ReFS File System, Multi-Tier Volumes and Erasure Coding
Like S2D, the ReFS file system actually isn’t new either, they have been working on it for several releases now also. In Windows Server 2016, it finally drops the tech preview label and is now ready for production. And there is a lot of benefits… like volume creation doesn’t have to zero out the volume for 10 minutes like NTFS. It’s just a metadata operation that is effectively instantaneous now, I’m just going to focus on the couple of benefits that ReFS has for S2D.
For those not familiar Erasure coding (EC) and to prepare you for the next part, EC is a method of data protection in which data is broken into fragments, expanded and encoded with redundant data pieces and stored across a set of different locations.
The original goal of EC was to enable data that becomes corrupted at some point in the storage process to be reconstructed by using information about the data that’s stored elsewhere. Erasure codes are great, because of their ability to reduce the time and overhead required to reconstruct data. The drawback of erasure coding is that it can be more CPU-intensive, and that can translate into increased latency.
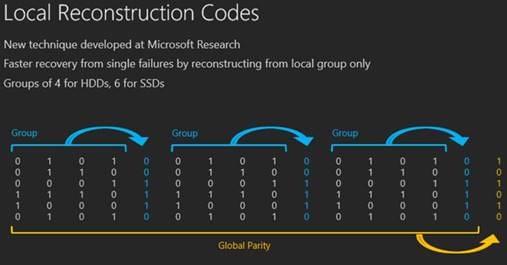
Now all that being said, classic erasure codes were designed and optimized more for communication, not for storage. Naively applying classic erasure codes in storage is okay, but is missing enormous efficiencies. Microsoft has developed their own erasure codes optimized for storage called Local Reconstruction Codes (LRC). I will cover this brieifly further down in the post.
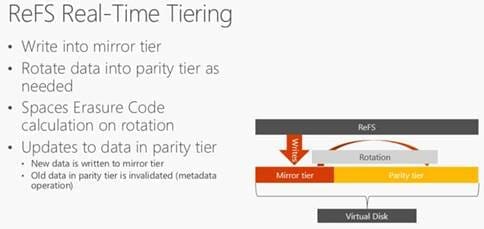
Now back on to S2D…For data protection, S2D uses either 3-way mirroring or distributed parity with EC. Mirroring gives you great write performance, but only 33% data efficiency. EC gives you good data efficiency, but random write performance isn’t great for hot data. ReFS supports the ability to combine different disk tiers using different parity schemes in the same vDisk. This allows S2D to do real-time data tiering by writing new data to the mirror tier and then automatically rotating cold data out to the parity tier and applying the erasure code on data rotation.
It is important to note that ReFS does not currently support Deduplication. There was a question on this in every session and MSFT says that this is all the ReFS is currently focused on. So we’ll expect to see it land in ReFSv3. For now, customers can get dedupe with S2D by using NTFS. 🙁

 Note if you only have two types of storage then the highest performing is used for the cache while the other type will be divided between performance and capacity with the different resiliency option (mirror vs parity) providing the performance/capacity difference between the tiers. If you only have one type of storage then the cache is disabled and the disks divided between performance and capacity like the previously mentioned case.
Note if you only have two types of storage then the highest performing is used for the cache while the other type will be divided between performance and capacity with the different resiliency option (mirror vs parity) providing the performance/capacity difference between the tiers. If you only have one type of storage then the cache is disabled and the disks divided between performance and capacity like the previously mentioned case.
For non-Storage Spaces Direct only two tiers, of storage are supported like Windows Server 2012 R2, i.e. SSD and HDD, there is no cache. If you had NVMe storage that could be the “hot” tier while the rest of storage (SSD, HDD) could be the “cold” tier (you name the tiers whatever you want) but you cannot use three tiers.


 During Ignite 2016, Microsoft took many shots at VMware. Microsoft said that there’s a right way and a wrong way to do erasure coding. “When you do it the wrong way, performance sucks and you have to limit it to all-flash configurations.”
During Ignite 2016, Microsoft took many shots at VMware. Microsoft said that there’s a right way and a wrong way to do erasure coding. “When you do it the wrong way, performance sucks and you have to limit it to all-flash configurations.”
Microsoft research is using a new technique called “Local Reconstruction Codes”. It uses smaller groups within the vDisk that allows them to recover from failures much faster by not having to reconstruct data from across the entire pool. This combined with multi-tier volumes gives S2D good performance, even on hybrid systems. Sounds like a technology that I seen before. Hmmm..I wonder where……. 😉
 Ok, that’s all for now. next up, Fault Tolerance and Multisite Replication with S2D….
Ok, that’s all for now. next up, Fault Tolerance and Multisite Replication with S2D….
Until Next time, Rob….